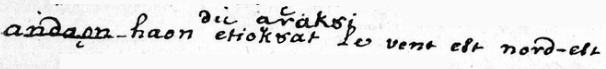6. Basic principles for transcription and encoding of manuscripts
What follows is an initial set of principles proposed prior to beginning the process of transcription and encoding. We expect these principles to develop and change as the team works with the real data.
6.1. What we transcribe and what we ignore
We are primarily interested in the dictionary entries, not in the manuscripts themselves as historical artifacts; as a result:
- We ignore front matter and back matter.
- We transcribe long s (ʃ) as regular s, unless there is a good reason to preserve it.
- We transcribe and encode deletions, substitutions, corrections and so on, using the <del>, <subst>, <choice>, <sic> and <corr> elements as explained in this documentation.
- We signal cases ambiguous or unclear text using the <unclear> tag, so that Megan can later go back and investigate them.
- We encode page-beginnings (using <pb> tags). These should be provided for you as part of the initial document structure
before transcription/encoding begins. Note that page-beginnings may appear in the middle of entries. This is perfectly OK; you do not need to close an entry before a page-break:
<entryFree>
[entry starts...]
<pb facs="#ms67-0004" n="4"/>
<unclear>something</unclear>
[entry continues...]
</entryFree>⚓ - We encode forme works (running titles at the top of pages etc.) where we believe this
might be helpful to the reader. For example, where the dictionary range of entries
in a page is shown at the top of the page, we encode it like this:
<pb facs="#ms60-0341" n="0341"/> <!-- Example of forme works encoding. --> <fw>Mal. Man.</fw>Forme works may appear in the middle of an entry or between entries.
- All uncommon abbreviations should be encoded with an <abbr> element. It is possible to provide an expansion in-place, using a <choice> structure like this:
<choice> <abbr>n.b.</abbr> <expan>nota bene</expan> </choice>However, most of the time, we cannot be sure what an abbreviation stands for, so we don't expand it; we just use the <abbr> tag. Obvious abbreviations (such as M. for Monsieur) do not require expansion either.
6.2. Basic document structure for manuscripts
6.3. Dictionary entries in manuscripts
Across our primary source documents, dictionary entries take a wide variety of forms, and are not necessarily structured consistently. For this reason, we take a loose approach to encoding, using the TEI element <entryFree> to wrap each entry, and then within that, tagging all the things that are important to us.
6.3.1. Wendat text: <form> elements
6.3.1.1. Names inside forms
6.3.2. Latin text
6.3.3. French text
All text which is not tagged as a <form> or as Latin text is assumed to be French. In other words, French text does not require any special tagging to identify it.
6.4. Language codes for manuscripts
In TEI XML, the language of a document or a part of a document is specified using the W3C's standard xml:lang attribute, which can appear on any TEI element. We use the following language codes as values for xml:lang attributes:
- en (English)
- fr (French)
- grc (Ancient Greek)
- la (Latin)
- wdt (Wendat)
- wyn (Wyandot)
- mul-x-enfr This is a custom tag created for use in this project specifically. The first component, mul, is a standard signifier for ‘multiple languages’. The -x- means that the following part is a project-specific custom value. The final part, enfr, means ‘English and French’. This is used for text which is written in a combination of English and French, which is how we handle creating multilingual pages for our site interface.
- mul-x-lafr This is a custom tag created for use in this project specifically. The first component, mul, is a standard signifier for ‘multiple languages’. The -x- means that the following part is a project-specific custom value. The final part, lafr, means ‘Latin and French’. This is used for text which is written in a combination of Latin and French, a fairly common situation.
*We are considering an application to change the registered code for Wendat to wdt; if that is successful, a simple search-and-replace will be sufficient to update the project.
6.5. Unclear text, deletions and inline style in manuscripts
Generally speaking, the only encoding we do is conceptual (identifying what things are rather than what they look like). However, it's sometimes important to capture the appearance of some text without actually knowing why it looks like it does.
You can use the <hi> element to do this, with the rendition attribute to say what the text looks like. So for italicized text:
<hi rendition="rnd:italic">This is italics.</hi> ⚓
for underlined text:
<hi rendition="rnd:uline">This is italics.</hi> ⚓
and for superscript:
<hi rendition="rnd:sup">This is superscript.</hi> ⚓
There are keystroke shortcuts for inserting these tags.
You will also come across text that has been deleted by strikethrough or by being scribbled over. Tag this with the <del> (deletion) element. Similarly, when you see text which is unclear, use the <unclear> element. You may of course use an <unclear> element inside a <del>, or vice versa. Again, there are keystroke shortcuts for these tags.
6.6. More complex insertions, deletions and corrections in manuscripts
Sometimes you will come across cases where text has been modified by the original author in puzzling ways. Here is an example:

Here, it's clear that the author has made corrections to the form. What matters here is what the intention is; we don't really care what was originally written in the bits which are blocked out, and we don't care that the ‘s’ character is written above and to the right of the ‘a’ character, because these are incidental features. We would transcribe this as:
achiaraskȣa⚓
In other words, as long as we can determine what the writer's intention is, we represent it as straightforwardly as possible. We might wrap this in an <unclear> element to signify that there is some possible doubt about it; perhaps the ‘s’ here is actually blocked out? It's hard to tell. But we don't worry about trying to represent the process which led to the final form.
In this example, text has been written in above the line:
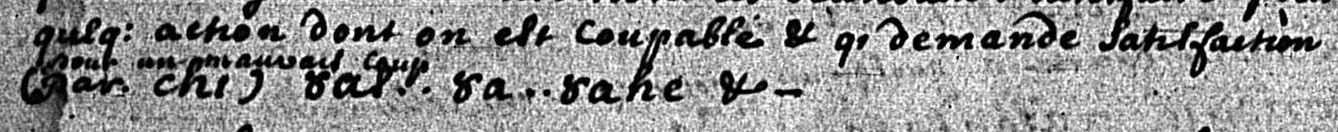
Here, the phrase ‘pour un mauvais coup’ has been written in between two lines. Here, our job is to determine where the writer intended to insert the phrase. Is it a continuation of the previous line, forming a continuous French phrase ‘qi demande Satisfaction pour un mauvais coup’? If so, we would transcribe it as:
...qi demande Satisfaction pour un mauvais coup (par chi)...⚓
Alternatively, perhaps the idea is to add that phrase after the first Wendat form. In that case, the transcription would be:
Satisfaction (par chi) <form>ȣas</form> pour un mauvais coup .. <form>ȣa .. ȣahe</form>⚓
In other words, we try to represent the intention of the writer insofar as we can determine it.
In this third example, we see what looks like a correction; the phrase ‘beaucoup d'eau’ has been crossed out, and the correction ‘de l'eau’ written above:
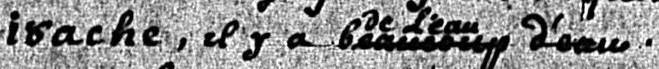
We could simply ignore the crossed-out text here and include only the phrase ‘de l'eau’, but it is intriguing that the writer made this particular change, and it may be useful; since we can easily see what the original was, we may as well transcribe this as a deletion and an addition:
...il y a <del>beaucoup d'eau</del> <add>de l'eau</add>⚓
In other cases, it may be difficult or impossible to determine what the writer intended by a particular configuration of characters. In the following example, there are several instances of the letter ‘r’ written above another letter:

The significance of this is not apparent, so rather than attempt to interpret the intention of the writer, it makes more sense simply to encode what you see. This is how you might do that:
This encoding captures the fact that the letter ‘r’ is written above the letter ‘h’, in a manner which suggests that they might represent different options. There is a keystroke shortcut that enables you to select the letters ‘hr’ and then insert this encoding automatically. In the rendered HTML version of the MS, the ‘r’ will be shown above the ‘h’. Here is another example, along with its encoding:
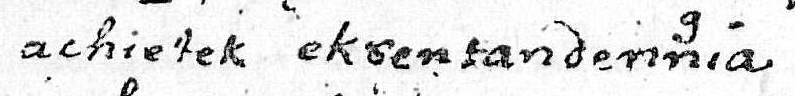
6.7. Lists, tables and complex layouts in manuscripts
The texts we work with are semi-formal manuscripts, often annotated and edited in multiple revision campaigns, so they present some significant challenges in terms of interpretation, transcription and encoding. Our primary aim when transcribing and encoding is to represent truthfully what we believe the original writer intended to convey. We are less interested in the minutiae and accidentals of scribal practice. Above all, we aim to make these difficult texts both readable and processable for our team and our audience.