In this presentation, I want to try to draw some conclusions about the overall practicality of TEI markup as the basis for scholarly publications by looking at one specific area of TEI, the encoding of bibliographical citations, to try to assess its suitability for the task of marking up born-digital scholarly documents for print and electronic publications.
(5) Entering items in Zotero
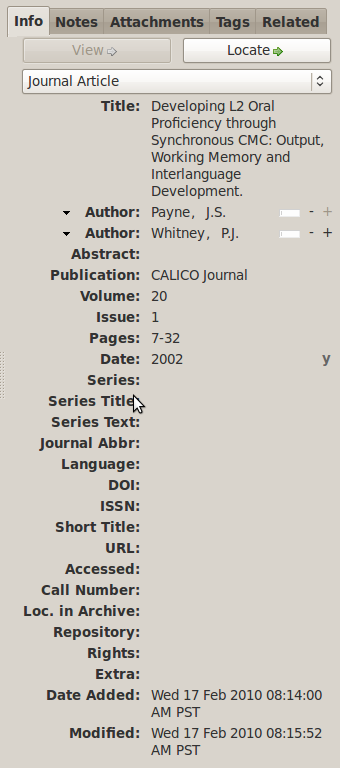
When you choose a specific item type, you get a customized data entry form for that item type, which is different from the others. For instance, if you're inputting a Journal Article, you get fields for volume, issue, pages, ISSN and so on; for a Radio Broadcast, you get Episode Number, Recording Type, Network, etc. Zotero needs to store these fields in discrete structures in order to fulfill its mission of exporting to a range of different formats and rendering for different styleguides.
(6) Entering a podcast in Zotero
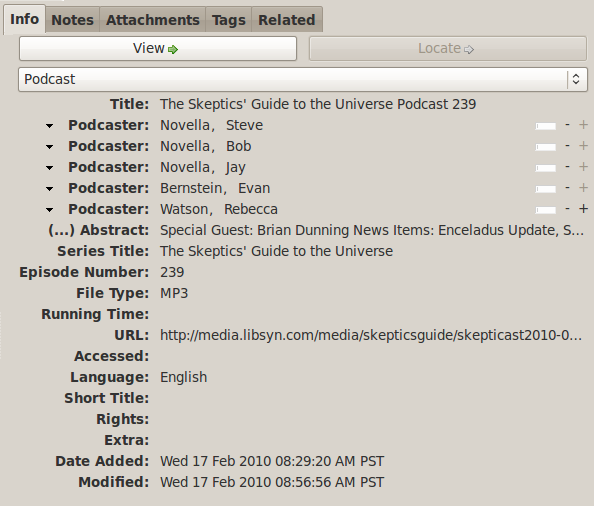
Here's the form for entering a podcast. You can see that a lot of the fields are specific to the item type or to similar types ("Podcaster", "File type", "Running time"). These specific fields are required when rendering for specific styleguides; for instance, to render this item according to the APA Styleguide to Electronic References, we need to know that it's a podcast (the word "podcast" appears in the rendering), we need to know its episode number, and we need the file URL. We also ought to have the date of the podcast itself, which is required by the APA rendering, but there's no field for that.
Zotero saves this data in an sqlite database, but it also has a "native" RDF file format. If we export this single item into "Zotero RDF", we get a document that uses 21 elements from 7 different namespaces. Exporting a collection of only six bibliographic items gets us 43 elements spread across 9 different namespaces.